In an e-commerce environment, there is a constant struggle between polar opposites that must be balanced and adjusted at all times. Some of those include:
- Customer Experience vs. Search Engine Experience
- Marketing Flexibility vs. IT Standardization
- Ease of Use vs. Security
When dealing with Ease of Use versus Security, you run into very interesting issues, one of which is the ability for a customer to come into your e-commerce storefront and validate their credit card. This simple transaction sounds great from a customer service perspective (who wouldn't want a customer to be able to know if their credit card is good or not?) but it becomes complicated in an online environment. A brick and mortar store has to contend with credit card fraud, but they at least have the privilege of looking the customer in the eye and seeing their credit card. They also can only fit one person at the counter at a time, which means the rate at which credit validations occurs is inherently limited or throttled.
Online this becomes an entirely different matter. It may cost $0.25 per "validation" to have VeriSign respond whether a credit card is valid or not and an adept hacker can slam through thousands of cards per second. You also can never truly be certain if they are holding that worn plastic card or they simply bought the list of credit card numbers from an offshore swindler.
The customer service benefit of saying, "Thank you but your credit card is not valid" now becomes an offensive weapon that a credit card hacker can use to sift through a list of made-up cards to determine which ones are valid or not. Your obligation as a good internet commerce citizen is to stop this behavior if you can, or at a minimum, slow them down and deliver as little information as possible.
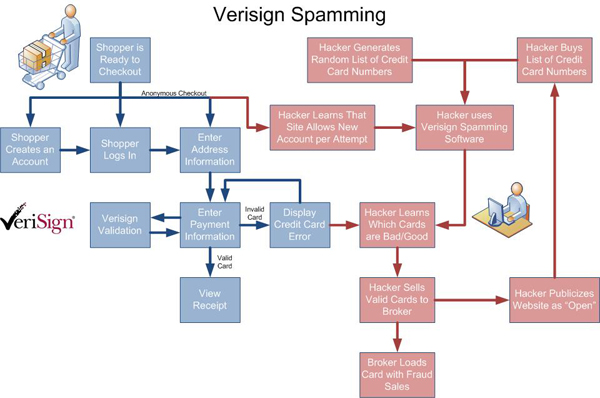
What does a hacker stand to benefit from Verisign Spamming? There are many obvious benefits and some that aren't so clear. Here is a diagram that demonstrates the many "openings" available to a Verisign spamming hacker:
In crowded neighborhoods where traffic is a problem, they use speed bumps... and the Internet equivalent of that is the "captcha". The word CAPTCHA is actually an acronym derived from the following: "Completely Automated Public Turing test to tell Computers and Humans Apart". A Turing Test is more aptly described in Wikipedia if you're curious...
Generally a CAPTCHA authentication can be very complex or relatively simple. For the purposes of a "speed bump" however, (and assuming you aren't working for the Nuclear Regulatory Commission) you don't need to do anything over the top. Here's a simple diagram of the standard payment process:
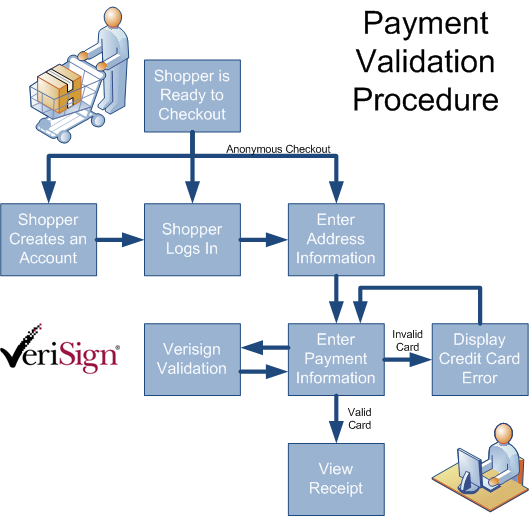
Naturally, a hacker can set a script to run through the above process with reckless abandon, either exploiting loose account creation rules, penetrating an existing registered user account, or abusing the anonymous checkout option for users. Once their script has entered the payment process, they can automate rapid-fire capture authorizations through the VeriSign validation mechanism in an effort to see which ones branch off to the "invalid card" page or the "valid card" page. Even a nuanced error message that attempts to kindly inform the customer of which field was entered incorrectly will deliver vital information to the hacker so they know what was (or wasn't) valid. Not only do VeriSign validations cost a quarter or so per "hit", depending on the order processing rules, you can even end up with tentative amounts frozen on the credit cards even if the transaction is rejected (an "Auth Capture").
This unfettered access needs a "traffic cop" to regulate the ease with which an automated script can burn through the payment and credit card validation procedure. Note the below implementation of a Captcha validator as a "speed bump" in the checkout process:
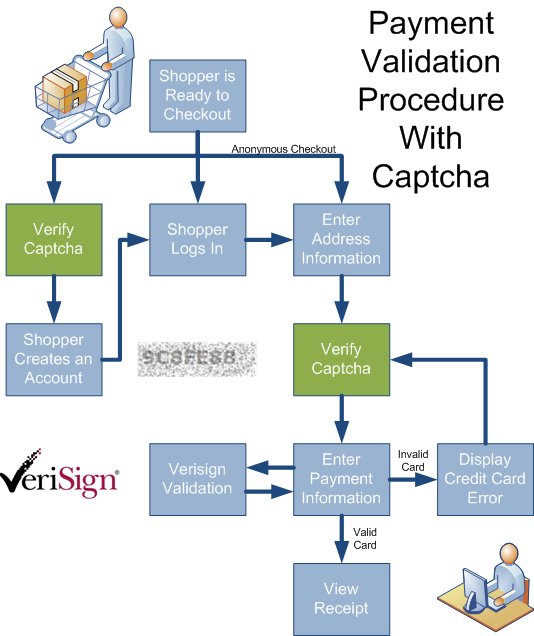
At a minimum, this prevents the hacker from obtaining an efficient and rich dataset from their list of stolen (or generated) credit card numbers and slows down their automated processing enough that hopefully they will move along to another website victim. Please note that this isn't the only mechanism to secure your e-commerce platform... just one of the pieces of the puzzle.
Generating the Captcha involves a few simple steps which I will outline below. I've been accused of being far too technical in these articles, so the remainder may be something you'll care to avoid...
 The purpose of a captcha is to obscure the borders of the letters and numbers so an automated OCR (Optical Character Recognition) routine can't read the text without a human being involved. The image also must be a single, complete image and not text overlaid in HTML over an image background so the text is obfuscated in the binary image file rather than "scrapeable" by some bot. Once the image is generated, its text must be matched on the other side with the "key" text that matches what was embedded into the image. If the customer enters the proper Captcha code, then the website can continue.
The purpose of a captcha is to obscure the borders of the letters and numbers so an automated OCR (Optical Character Recognition) routine can't read the text without a human being involved. The image also must be a single, complete image and not text overlaid in HTML over an image background so the text is obfuscated in the binary image file rather than "scrapeable" by some bot. Once the image is generated, its text must be matched on the other side with the "key" text that matches what was embedded into the image. If the customer enters the proper Captcha code, then the website can continue.
The first step is to create the table that will house the valid pool of Captcha numbers in SQL Server 2005:
CREATE TABLE [Captcha]( [ID] [uniqueidentifier] ROWGUIDCOL NOT NULL CONSTRAINT [DF_Captcha_ID] DEFAULT (newid()), [Status] [int] NULL, CONSTRAINT [PK_Captcha] PRIMARY KEY CLUSTERED ( [ID] ASC )
The second step is to create the stored procedure that will generate the Captcha code. I'm going to borrow a t-SQL script for SQL Server 2005 that I used to demonstrate the passing of XML parameter data in lieu of normal parameters to stored procedures as shown below:
CREATE PROCEDURE [Captcha] @Parameters xml AS SET NOCOUNT ON; ------------------------------------------------------------------------------------------------------------------ -- Valid XML Parameter Definitions ------------------------------------------------------------------------------------------------------------------ -- <security type="1" version="1"> -- <request> -- <!-- Methods --> -- <parameter name="Action" class="method">Get</parameter> -- <!-- Constants - Settings --> -- <parameter name="Precision" class="constant">7</parameter> -- </request> -- </security> ------------------------------------------------------------------------------------------------------------------ -- Valid Security Values type version ------------------------------------------------------------------------------------------------------------------ -- 1-captcha 1-current ------------------------------------------------------------------------------------------------------------------ -- Valid Parameter Values class match id name ------------------------------------------------------------------------------------------------------------------ -- table starts-with GUID identifier (listed above) -- constant ends-with -- property equals -- method contains ------------------------------------------------------------------------------------------------------------------ -- Valid Method Values Actions ------------------------------------------------------------------------------------------------------------------ -- Get -- Validate -- Regenerate ------------------------------------------------------------------------------------------------------------------ -- TEST CASES ------------------------------------------------------------------------------------------------------------------ -- Standard Captcha Request ------------------------------------------------------------------------------------------------------------------ /* exec Captcha ' <security type="1" version="1"> <request> <parameter name="Action" class="method">Get</parameter> <parameter name="Precision" class="constant" match="equal-to">7</parameter> </request> </security>' */ ------------------------------------------------------------------------------------------------------------------ -- Standard Captcha Validate ------------------------------------------------------------------------------------------------------------------ /* exec Captcha ' <security type="1" version="1"> <request> <parameter name="Action" class="method">Validate</parameter> <parameter name="Token" class="constant" match="equal-to">47842F8</parameter> </request> </security>' */ ------------------------------------------------------------------------------------------------------------------ -- Standard Captcha Regenerate ------------------------------------------------------------------------------------------------------------------ /* exec Captcha ' <security type="1" version="1"> <request> <parameter name="Action" class="method">Regenerate</parameter> </request> </security>' */ ------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------- -- Temp Table Variable to Store incoming Parameters -------------------------------------------------------------------------------- DECLARE @tParameters TABLE ( [Name] [nvarchar](64) NULL, [Class] [nvarchar](32) NULL, [Match] [nvarchar](32) DEFAULT 'contains' NULL, [Value] [nvarchar](max) NULL, [ID] [uniqueidentifier] NULL ) -------------------------------------------------------------------------------- -- Deposit Incoming Parameters into temp Table Variable -------------------------------------------------------------------------------- INSERT INTO @tParameters ([Name], [Class], [Match], [Value], [ID]) SELECT P.parameter.value('@name', 'nvarchar(64)') , P.parameter.value('@class', 'nvarchar(32)') , P.parameter.value('@match', 'nvarchar(32)') , P.parameter.value('.', 'nvarchar(max)') , P.parameter.value('@ID', 'uniqueidentifier') FROM @Parameters.nodes('/captcha/request/parameter') P(parameter) -------------------------------------------------------------------------------- IF 'get' = Lower((SELECT Value FROM @tParameters WHERE Name='Action' and class='method')) BEGIN SELECT TOP 1 LEFT(REPLACE(C.ID,'-',''),P.value) FROM Captcha C , @tParameters P WHERE P.Name='Precision' ORDER BY NEWID() RETURN END -------------------------------------------------------------------------------- IF 'validate' = Lower((SELECT Value FROM @tParameters WHERE Name='Action' and class='method')) BEGIN SELECT COUNT(C.ID) FROM Captcha C WHERE C.ID LIKE (SELECT Value FROM @tParameters WHERE Name='Token') + '%' RETURN END -------------------------------------------------------------------------------- IF 'regenerate' = Lower((SELECT Value FROM @tParameters WHERE Name='Action' and class='method')) BEGIN DELETE Captcha INSERT INTO Captcha (status) SELECT TOP 100 1 FROM product -- or other table containing at least 100 rowsets SELECT COUNT(ID) TokenCount FROM Captcha RETURN END --------------------------------------------------------------------------------
This stored procedure encapsulates the three valid methods that can be used for Captcha validation:
- Get a random Captcha token from the authorized pool of valid Captcha numbers.
- Test an incoming token against the authorized pool of valid Captcha numbers
- Regenerate the pool of valid Captcha numbers (to foil any scripts that happen to figure out some of the codes)
Now that we have deployed the table, the stored procedure is ready to "take our orders", and we have the Captcha background in place ( )... then we are ready to deploy the code necessary to generate the image, merge it with the valid Captcha token, and display it.
)... then we are ready to deploy the code necessary to generate the image, merge it with the valid Captcha token, and display it.
Note we are using the System.Drawing namespace here to read in the background, overlay the image with a "watermark" containing the Captcha token that is retrieved from the database, and then delivering that in a binary stream. If this .aspx file were called "Captcha.aspx" then the resulting image that referenced this in HTML would be <img src=captcha.aspx"/>.
using System;using System.Configuration;using System.Data;using System.Data.SqlClient;using System.Drawing;using System.Drawing.Drawing2D;using System.Drawing.Imaging;using System.IO;public partial class captcha : System.Web.UI.Page{ //Default DataSource private static string connectionString = ConfigurationManager.ConnectionStrings["database"].ConnectionString; protected void Page_Load(object sender, EventArgs e) { const string NOT_AVAILABLE_IMG_NAME = "NotAvailable.jpg"; try { Image image = Image.FromFile(Server.MapPath("captchaBackground.jpg")); image = image.GetThumbnailImage(image.Width, image.Height, new Image.GetThumbnailImageAbort(ThumbnailCallback), IntPtr.Zero); image = AddWatermark(image, 0, 10); Response.ContentType = "image/jpeg"; image.Save(Response.OutputStream, ImageFormat.Jpeg); } catch { Image errorImage = Image.FromFile(Server.MapPath(NOT_AVAILABLE_IMG_NAME)); Response.ContentType = "image/jpeg"; errorImage.Save(Response.OutputStream, ImageFormat.Jpeg); } } private static Image AddWatermark(Image currImage, Int32 targetWidth, Int32 targetHeight) { Graphics g = Graphics.FromImage(currImage); Font watermarkFont; String watermarkText = GetData(); watermarkFont = new Font("Verdana", 14, FontStyle.Bold); g.InterpolationMode = InterpolationMode.HighQualityBicubic; g.DrawImage(currImage, 0, 0, targetWidth, targetHeight); g.SmoothingMode = SmoothingMode.HighQuality; SolidBrush foregroundText = new SolidBrush(Color.FromArgb(100, 0, 0, 0)); SolidBrush backgroundText = new SolidBrush(Color.FromArgb(50, 255, 255, 255)); g.DrawString(watermarkText, watermarkFont, backgroundText, Convert.ToSingle(targetWidth / 2), Convert.ToSingle(targetHeight / 2)); g.DrawString(watermarkText, watermarkFont, foregroundText, Convert.ToSingle(targetWidth / 2) + 2, Convert.ToSingle(targetHeight / 2) - 2); return currImage; } static Boolean ThumbnailCallback() { return true; } private static String GetData() { SqlConnection conn = null; try { conn = new SqlConnection(connectionString); conn.Open(); SqlCommand cmd = new SqlCommand("Captcha", conn); cmd.CommandType = CommandType.StoredProcedure; String parameters = "<captcha><request><parameter name=\"Action\" class=\"method\">Get</parameter><parameter name=\"Precision\" class=\"constant\" match=\"equal-to\">7</parameter></request></captcha>"; cmd.Parameters.Add(new SqlParameter("@Parameters", parameters)); return (String)cmd.ExecuteScalar(); } finally { if (conn != null) { conn.Close(); } } }}
There is more work to be done to integrate this Captcha image into the page and check against the stored procedure shown above to validate it... and apply some business logic, but I hope this article has given you a sense of how to generate the Captcha, and what it's purposes are.
There are many other resources for professionally designed Captcha integrations including some fun ones I liked (and some "gotchas" I thought were funny...):