This is the second installment in a series that blends website architecture, data structures, and SEO marketing into a collaborative design pattern continuing from Part 1 - Best Business Practices for Product Catalog Data Structures - Atomic Data
We've discussed some ways you can create highly discrete or "atomic" data for a product in the first article. This article will delve into how to evaluate the choices involved in speed versus flexibility.
Any database administrator that works on a high volume, high production website will simply start to quiver uncontrollably however, because there are severe implications for accessing this type of data scattered throughout several tables in a production environment. Pass him a mug of decaf and let's walk together through how we can tackle the thorny issue of speed related to product catalog data.
We can start with our sample product that we have now mapped into its discrete elements.
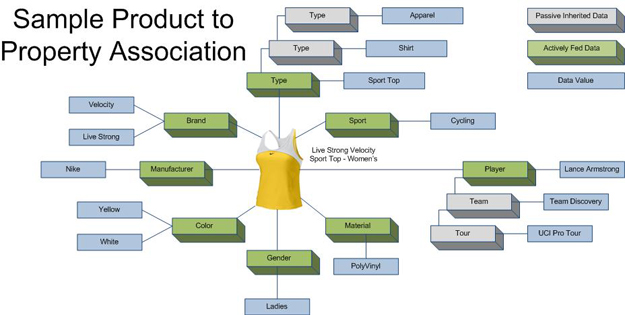
This data is fairly granular (or atomic) and is highly reusable within its domain ("Color" categorically means a similar thing to every product that is bound to it). There are many considerations when it comes to allowing Speed to dictate your design, but I'll list some of the top ones:
-
Static Edge Presentation vs. Dynamic Source Presentation
-
Precomputation or Data Summarization
-
Staged Caching or Static Publishing
Static Edge Presentation
Static Edge Presentation refers to the concept that data that is requested through web pages goes through many stages. One model that many people are familiar with is the following:
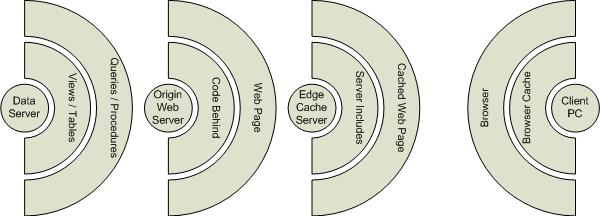
Generally when the first hit is generated for a distinct URL, such as http://www.domainname.com/?ID=5, the Data Server generates the data needed for the page, the Origin Web Server composes the data into a functional web page, and then the Edge Cache Server distributes that origin page into its "cache" where the unique page sits in "static" for all subsequent hits. If the page is requested from hundreds of Client PCs after that, only the Edge Cache Server responds to the request (until its cache expires). If a single Client PC hits refresh over and over again, depending on the Client PC settings, the page is instead served from the Client PC's Browser Cache, which is a local equivalent of server-based edge caching. This is generally one of the more advanced methods of serving high volume pages in a fast manner (and in a way that the database is impacted the least). This is the preferred shield which allows your data structures to be a bit more complex (read slow), because at the price of the initial render, the cost per page load is mitigated by the Edge Caching.
Take a page that requires 8 seconds to load. This is generally considered "too heavy" of a page to be used in production environments. However, this is only the Origin Page Render cost, meaning it only "costs" this much time for the very first load of that unique page. If all subsequent page loads only take 0.5 seconds from the Edge Cache for all subsequent hits, then averaged over the numbers of hits, you can quickly see how the page load time continues to approximate the 0.5 seconds load time overall for the page.
Another model is the Dynamic Rendered Page which is far more common to most web developers and online businesses:
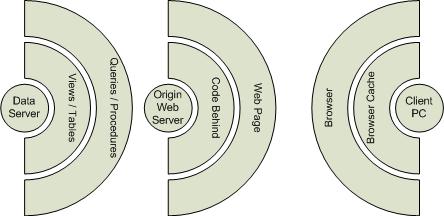
This model demonstrates the direct nature of the requests from the Client PC, straight to the Origin Web Server (which gets its data from the Data Server). In this model, there is generally a one-to-one relationship between the "hit" and the "data request", so the load on the database server is relatively high. There are tricks you can use to ameliorate this, including Origin Server Caching, SQL Dependency Caching, and other methods, but most implementations use this form of dynamic page delivery. In this case, data structures that cause delays can severely impact the performance of the application.
Take a page now, which due to its flatter data model, only costs a 3 second load time. Because the Edge Cache has been removed from the architecture, your average page load time is going to remain 3 seconds (the page construction happens over and over again for each hit). While you gain some flexibility by having constantly changing data available on the page, you pay in the overall load on your servers (up to six times more costly in time than an edge cached solution), and you also are forced into a far less flexible data model to compensate for the speed requirements of live rendered pages.
Precomputation
The concept of pre-computation is based on a similar concept as caching. This means that pretty much anything your database is going to need to "think" about, can in many cases be "pre-thunk." The art of pre-thinking things before they are needed involves storing what's been thought out and saving it somewhere. You also have to factor in the speed of retrieving things... some methods of storage are faster than others.
The diagram below (Self Healing Data Retrieval) shows the "layers" that a data request goes through before a page can be rendered. It's pretty clear that the fastest way to get data to the customer is when the customer asks for a webpage that has been "pre-thunk" already and is waiting in cache at the Edge Cache (Akamai for example). Here's where the magic happens. If the page is not available in cache, the Edge cache forwards the request to the Webserver. The Webserver then can not only generate the page, but it "heals" the Edge Cache by delivering the new page so any subsequent hits to the same page are now "healed" and available on the Edge Cache again.
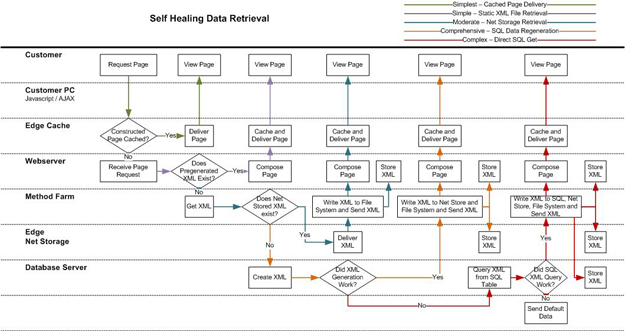
This type of failover I described above cascades all the way up to the top. In the examples above, if the Edge Cache fails, the Webserver picks up the slack. If the Webserver fails, then the Method Farm system checks to see if it has an XML representation of the data in memory (extremely fast). If the Method Farm doesn't have it in memory, then the Edge Net Storage picks up the slack. If the Edge Net Storage doesn't have the data, then the Method Farm checks to see if it has it saved in a file on the hard drive (pretty fast). If the Method Farm doesn't have it written to disk, then the SQL Server attempts to pull a static, pre-generated copy from a static table. If the static table doesn't have the data, then the SQL server regenerates the data. In general the failover escalation follows this model:
-
Edge Cache Static Copy
-
Webserver XML
-
Method Farm Memory XML
-
Edge Net Storage XML
-
Method Farm XML from file
-
SQL Server Static Record
-
SQL Server Dynamic Generation from data
In any of these cases, each step is design to "repair" the previous caller that failed. This ensures that over time, the vast majority of requests are being serviced by the Edge Cache Server and approaches near 100% availability.
Static Publishing
The last method of high volume, high speed retrieval of web pages that can help reduce load on database systems is the Static Publishing technique. This means that without waiting for for a user to request a page, the system is designed to "spit out" every single possible page and page combination that could possibly be hit and this entire pile of page data is dumped onto an edge cache somewhere. There is certainly some value to this, particularly for legacy media archives and other non-dynamic, and non-live page data, but it's use is extremely limited in the e-Commerce arena.
This highlights to some degree the ways in which network and publishing architecture can drive decisions of data structures in general. If you choose a more normalized method of data structure, then you need to compensate on the performance side with effective edge caching. If you choose a more dynamic method of page delivery, then you need to look more toward a flatter, more static form of data model that can deliver the performance that you need. Many database administrators will tell you that the atomic data model listed above (Sample Product to Property Association) may be too normalized for high volume use, but if the data being accessed is used to serve up pages for an edge cache architecture, the negative is eliminated.
It is important to factor in all of the requirements of your web project before making final data architecture decisions, but it is important to note that deficiencies in one decision (choosing a more normalized data structure) can easily be offset in other ways (choosing edge caching over dynamic page construction). This may give you more freedom as you make your data structure and architecture choices.
Now that you have evaluated your choices of data models and a highly normalized method is a good architectural choice for your situation, it's prudent to examine the benefits of what the data model will enable you to do. We will examine some of these benefits in Part 3 - Best Business Practices for Product Catalog Data Structures - Customer Paths.
