Atomic Data makes search engine dominance possible
 Online retail is not the same as brick and mortar retail. When a brick and mortar store launches online they fall into this biggest trap. Take an apparel shop… when you first walk in you find a men’s department and a ladies department. The store is physically trying to demographically segment you.
Online retail is not the same as brick and mortar retail. When a brick and mortar store launches online they fall into this biggest trap. Take an apparel shop… when you first walk in you find a men’s department and a ladies department. The store is physically trying to demographically segment you.
If you create a data model that matches this, you will end up with the first <xml> node being <gender> which is a highly limiting path to follow for a search engine even though it may make the most sense for a human being. You would then add data for teams, sports, colors, sizes, variants, materials of manufacture, and many other “parameters” for this data. To avoid 3rd normal database limitation, you would start to peel this data out into separate tables… one for colors… one for teams…one for sports. Then you would need to create many-to-many crosslink tables. Over time, your table count just gets larger and larger as new needs arise.
The Root Object Classification
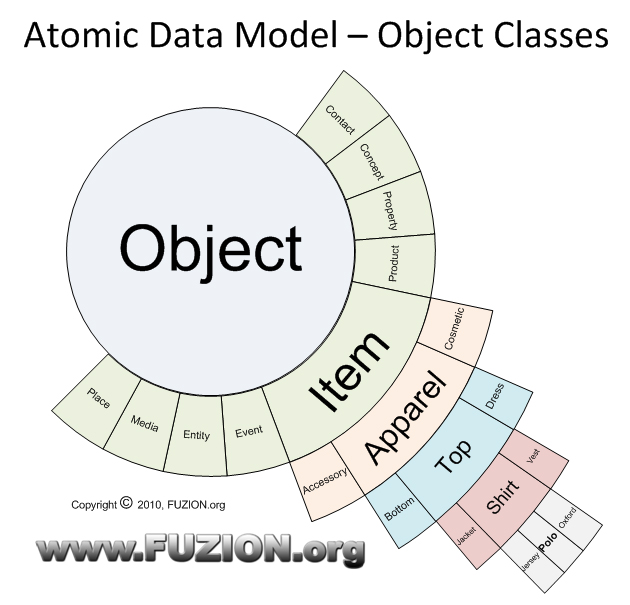 There is certain data that “hangs” off each sub-classification. In this example the Item class stores who the manufacturer is (because most items have manufacturers). The Apparel class contains the style information (because style is global to all apparel objects), whereas the Shirt class contains collar styles, sleeve variants, etc.
There is certain data that “hangs” off each sub-classification. In this example the Item class stores who the manufacturer is (because most items have manufacturers). The Apparel class contains the style information (because style is global to all apparel objects), whereas the Shirt class contains collar styles, sleeve variants, etc.
By localizing this information to class levels, once I define a “field” for the Apparel class, all future objects that inherit from that class will inherit that field. Any objects that do not inherit from the Apparel class will not have the field at all.
Note how different this is from a traditional 3rd normal representation of data where we would have fields like “color1” and “color2” and “color3” simply to leave enough fields available just in case we might need them for a particular product application.
Maximum Flexibility for Customer Paths
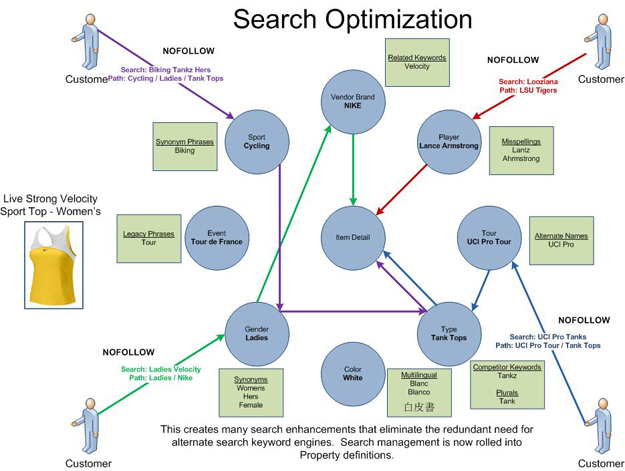
Now that our data is structured with infinite flexibility while still retaining a core hierarchy (for default navigation purposes), when a customer walks into our store, we can simply ask Google “how they sent them” to us… and what keywords they used. Now when the customer enters our “store” we can toss all of the inventory up into the air and literally rebuild our store to match the words they used in the order they used them. Now they can enter as “ladies yellow tank top” and we structure our product data in terms of gender first, color next and product class third… but we also can welcome customers that ask for “white womens Nike shirt” which we do by scanning for aliases of class nodes, parent classes, and other permutations of the item for maximum comfort to the customer and higher conversion rates on sales.
Know a business that would benefit from our whitepaper on how Atomic Data Modeling can make search engine optimization possible? Download it now:
02-Atomic-Data-Enables-Search-Engine-Dominance-by-FUZION.pdf (369.99 kb)
They call it a website for a reason
 Most first-time websites are designed with some flawed theories in mind. The theoretical flaw is that the homepage must lead the customer quickly to what they were looking for which assumes that the customer enters at the homepage and then discovers what they need by clicking. This “rapid funnel” concept is based on the idea that a customer doesn’t have the patience to “click through” too many pages and the site should be designed to streamline that as much as possible. While the idea has some merit for the customer interaction, the biggest flaw is that customers simply do not enter your website through the homepage at all (at least the vast majority of them).
Most first-time websites are designed with some flawed theories in mind. The theoretical flaw is that the homepage must lead the customer quickly to what they were looking for which assumes that the customer enters at the homepage and then discovers what they need by clicking. This “rapid funnel” concept is based on the idea that a customer doesn’t have the patience to “click through” too many pages and the site should be designed to streamline that as much as possible. While the idea has some merit for the customer interaction, the biggest flaw is that customers simply do not enter your website through the homepage at all (at least the vast majority of them).
The Homepage is the Least Important Page of your Site
We will use the www.JaxTires.com website as the example to illustrate this. If a customer owns a car in Jacksonville, Florida, they might think to type in www.JaxTires.com, but the vast majority are simply going to visit Google and type in “new tires Honda Accord” to find the specific product that they want. If a website were a funnel, we would force them to enter at our homepage, click on Vehicles, then Honda, then Accord, then Tires. In actuality, they click on Google, enter their search, find the results, and then they land directly on the specific item page for the Honda Accord at www.JaxTires.com. Instead of the website funneling the traffic to the specific page, the tens of thousands of specific pages expanded out from the center like a web, trapping the web surfing customer with a highly specific keyword that best matched their search.
You can see now how the homepage’s job is not to be all things for all people… It’s simply the very center of the web that spawns out threads in circles around it in a web form with the purpose being to “capture” every possible web searcher and land them on the most specific, most highly targeted page. The larger the expansion of that web and the more comprehensive the possible combinations, the more apt your website is to trap the flies that are buzzing around.
The Most Lucrative Keywords are the Most Specific Ones
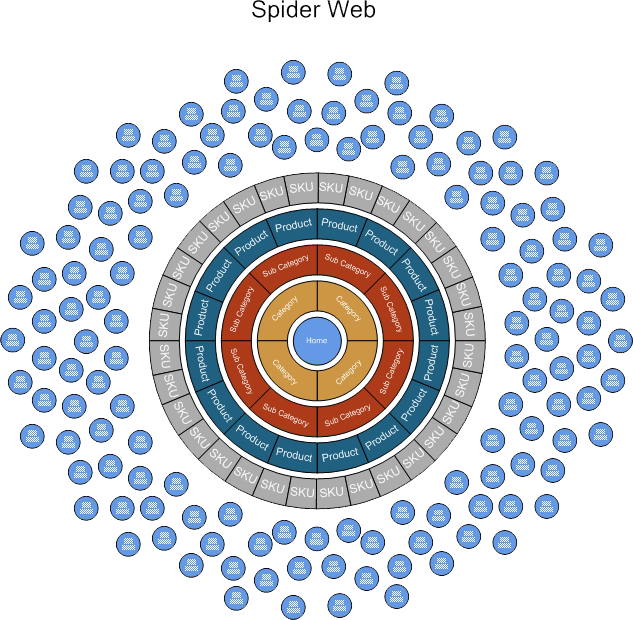 Let’s take a look at an alternate way of looking at a website. Here we have a diagram that more clearly explains how entry into the website actually happens. Instead of making our homepage a “catch-all” with tons of keywords loaded onto that one page (a common mistake), we have a tightly focused homepage whose subpages lose focus and their specific targeting the closer to the outside that we get.
Let’s take a look at an alternate way of looking at a website. Here we have a diagram that more clearly explains how entry into the website actually happens. Instead of making our homepage a “catch-all” with tons of keywords loaded onto that one page (a common mistake), we have a tightly focused homepage whose subpages lose focus and their specific targeting the closer to the outside that we get.
We now have millions of possible combinations of keywords that interlink like a spider web, lying in wait for a web searcher to put in that highly specific keyword combination… and once they do, they are landed artfully onto the very specific page that matched their search… not some general purpose “inbox” like most homepages.
Focus less on your homepage, and more on your specific micropages…
06-A-Website-is-a-web-Not-a-Funnel-Jared-Nielsen-FUZION.pdf (391KB)