This is the seventh installment in a series that blends website architecture, data structures, and SEO marketing into a collaborative design pattern continuing from SEO Weighted Auto Mapping - Best Practices for Web Product Catalogs - Part 6.
I initially intended to stop at Part 6 but as I continued to think about the usefulness of highly atomic product catalog data for e-Commerce catalogs, I began to think about how to use that information in more ways. Dr. Flint McLaughlin commonly teaches a theory he calls the "Marketing Experiments Optimization Methodology":
![]()
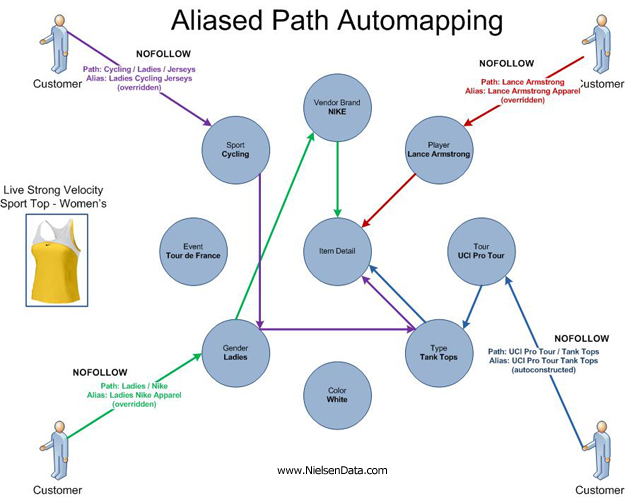
He obviously can explain it far better than I can, but the general rule is that your first priority is to optimize your product (and it's value proposition), followed by the presentation of that product, followed by optimizing the channels through which the product is sold. I will certainly investigate the first two, but if you focus solely on the "Channels" aspect of this, let's think about how our Product Property data can help us optimize our Marketing Channels. I'll revisit one of my earlier diagrams that shows the various paths that can be traveled to finally land on a product. This concept that the customer can "come from anywhere" and is going to want complete flexibility in how they choose to travel through your website is just as valid for other websites that show your products as well.
Consider a model where we have completed our website, we have optimized it for the search engines, and we are generating significant traffic. Jared's First Law of e-Commerce states (yes, I just made that up...) that it is illegal to make money on the Internet. The United States Treasury is the only institution entitled to "make money"... so our real objective is not to "make" money... but to "divert" money from other places so we get that money. If you think of your e-Commerce project in that light, it refocuses some of your goals. Now that we know that our job is to divert money that people would have otherwise spent somewhere else... what are the best tactics to accomplish this?
One of the primary mechanisms for this is called Product Feed Syndication. Syndication reminds me of Gary Larsen penning a Far Side comic strip. He spent his time creating a quality comic strip, but he didn't call up every newspaper and ask them individually to print them in their papers. He used a Syndicator or an Agent whose job was to do that for him. In similar fashion, you've created your entire e-Commerce catalog with rich product information and you've published your own website containing them... but you're not the Wall Street Journal quite yet...are you? That means that the vast majority of eyeballs that may be interested in your products are cruising through other websites than your own and you need to divert them to you.
Syndication Product Feeds are taps into your database that compose the products, their details, and their categorizations in a format that is consumable by the various feed agents (or syndicators). These can take several forms which I like to classify as:
-
Comparison Search Engines
-
Online Marketplaces
-
Product Review Sites
This article will primarily address the Comparison Search Engines but some of the principles can apply to the others.
Comparison Search Engines serve an important role in helping you expand your Channel Footprint. Basically, if you're the mom-and-pop shop on the corner, the Comparison Search Engines are the mall in downtown (some larger and more useful than others) and it's useful to have a presence in both places.
The challenge you have with Comparison Search Engines is they too require navigation paths. They may call them "categorizations" or "paths" or "trees" but they map directly to the Paths described in the diagram above (Aliased Path Automapping) just like they do on your own website.... with the exception that their paths are going to differ from yours in many cases. One good example is the path that many Comparison Search Engines use for Sports Apparel. They start with "Apparel", then continue to "Sports" and then to "Cycling" and so on. However, they also provide paths that start with "Sports", continue with "Cycling", and then "Apparel" which really contains the same product mix as the one before. Many feeds have a very flat structure to them, meaning that for each product, you may be able to specify four separate "Paths" that will be submitted with that product to the Comparison Search Engines.
Because our Product Property data is atomic and weighted, we can simply query out the top four weighted paths from our database for each product and layer that into our feeds to the Comparison Search Engines.
We can also tightly couple our Property mappings to their Paths or Categorizations by dissecting their Paths into their component parts. If a Comparison Search Engine has a root level of "Apparel", we can match that to our Property Type of "Apparel". That can form the basis of our query then that only pulls the top four weighted paths for that product that originates with the Apparel Property Mapping. If you really want to get aggressive on each Comparison Search Engine, then you could layer in a direct mapping from the Product Properties to each and every path variation provided by each Comparison Search Engine categorization.
As I have time, I'll try to revisit this article and distill some more useful information about the various Comparison Search Engines and how to feed each one.
Once you have mastered the Comparison Search Engine syndication feed, we can continue to leverage our Atomic Product Data in Online Marketplaces and Auction Sites - Best Practices for Web Product Catalogs - Part 8.